4年春休み期間に,vitについて少し勉強
詳しくみる
不均衡に関するクラス分類について調査
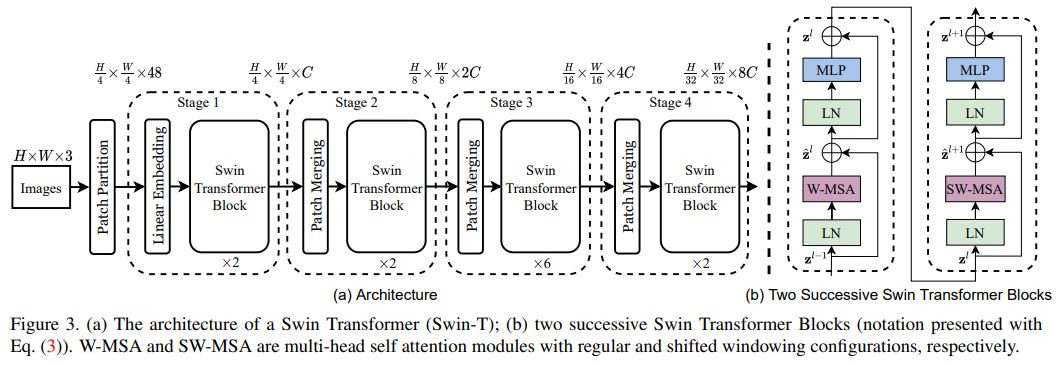
Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
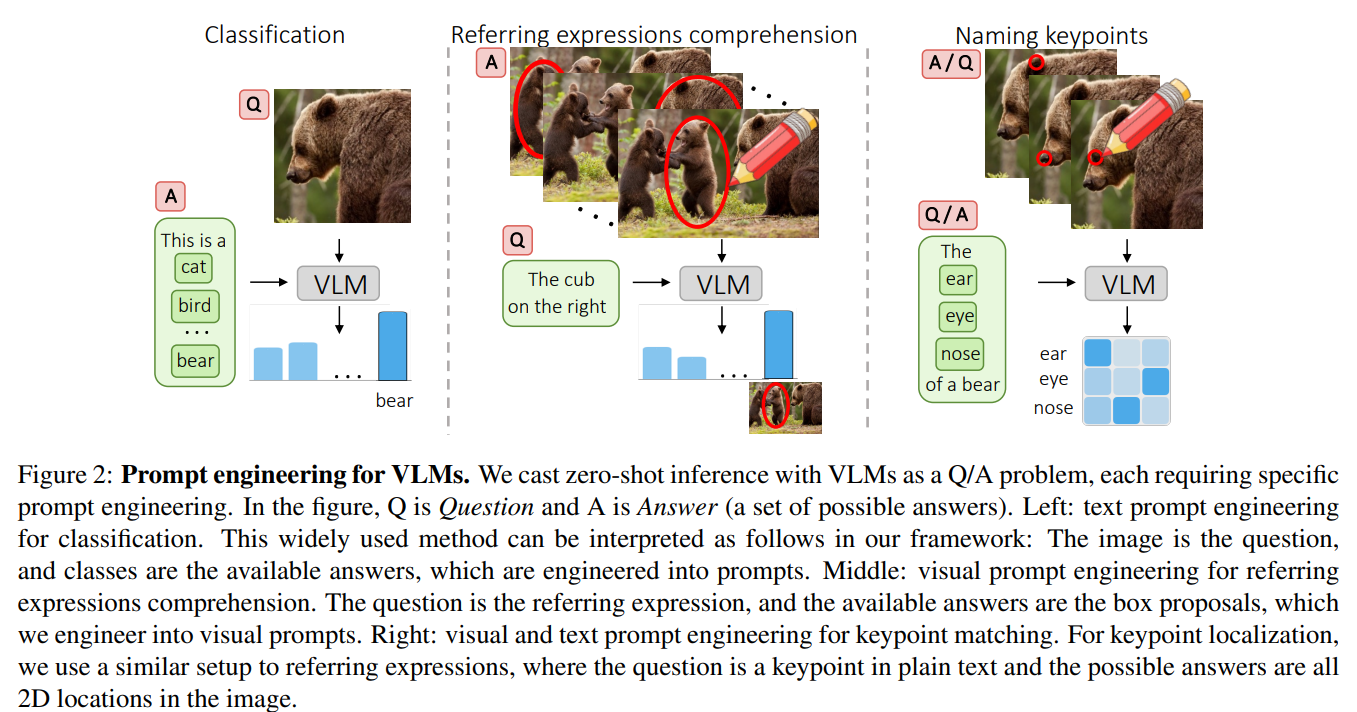
What does CLIP know about a red circle? Visual prompt engineering for VLMs
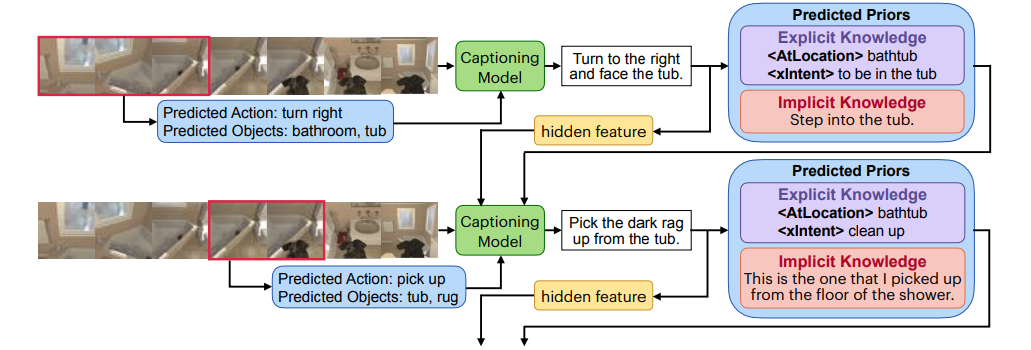
Implicit and Explicit Commonsense for Multi-sentence Video Captioning
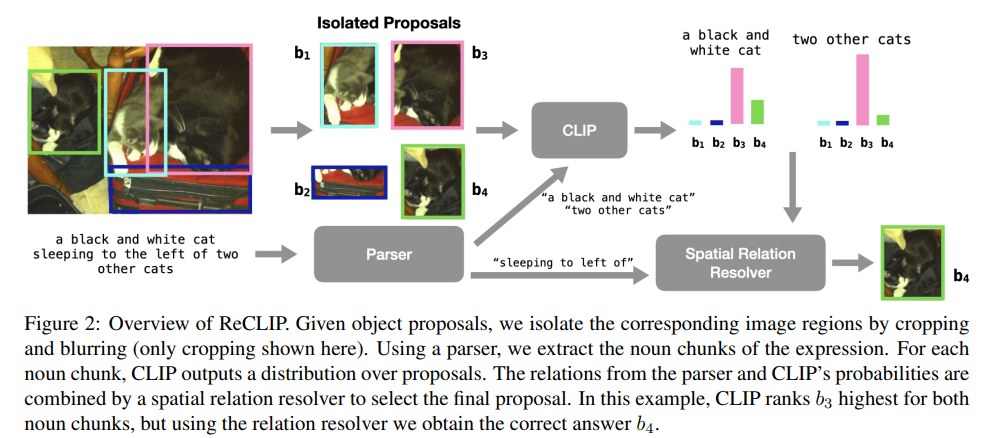
ReCLIP: A Strong Zero-Shot Baseline for Referring Expression Comprehension
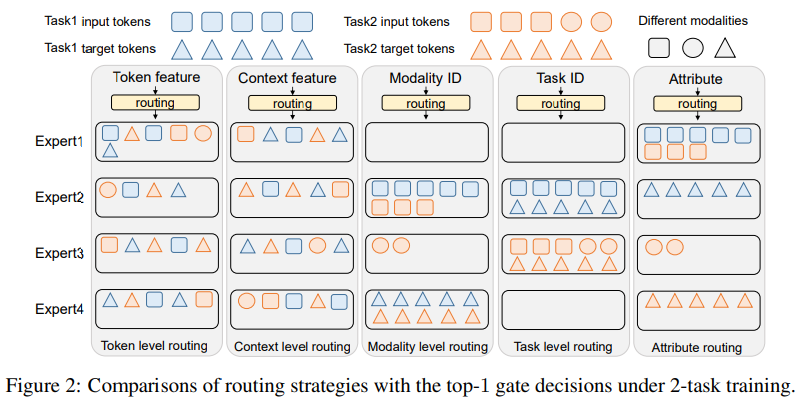
Uni-Perceiver-MoE: Learning Sparse Generalist Models with Conditional MoEs
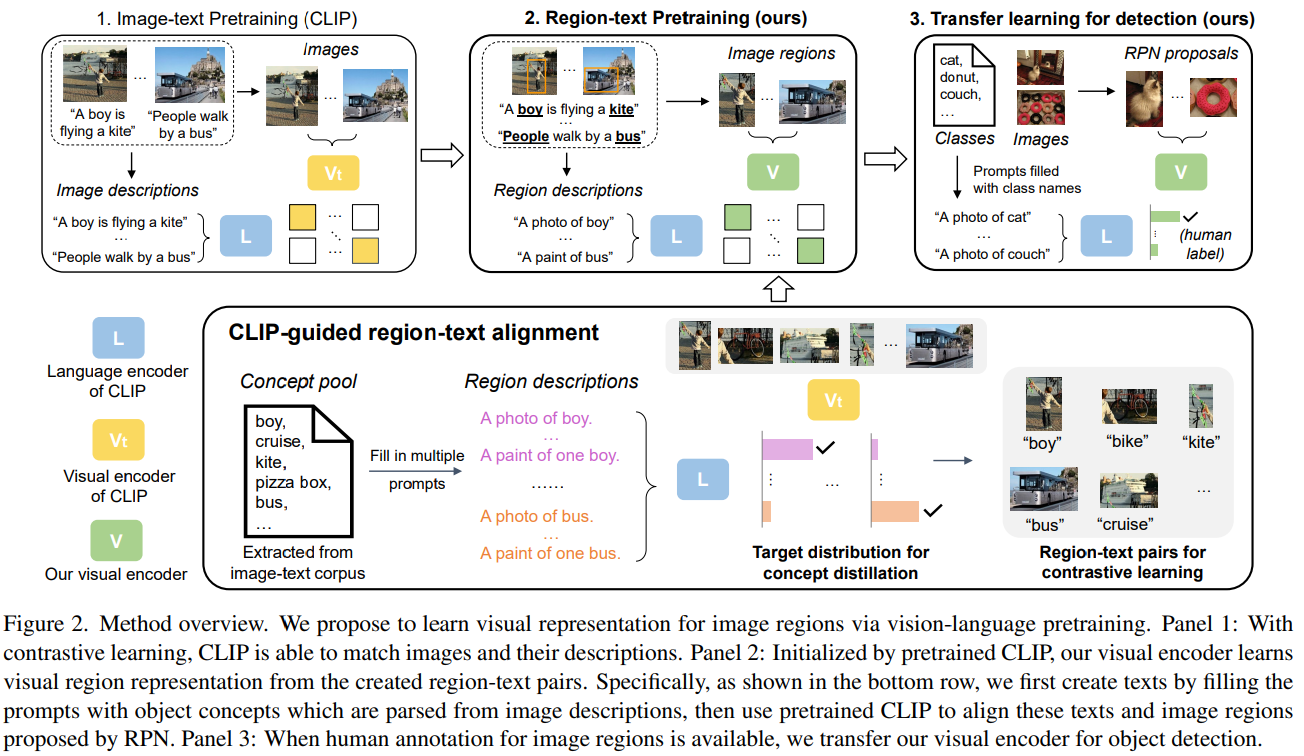
RegionCLIP: Region-based Language-Image Pretraining